.png)


Executive Summary
Google Cloud Next 26 ran April 22-24 in Las Vegas and delivered 260 product announcements. The three themes that matter for engineering and FinOps teams:
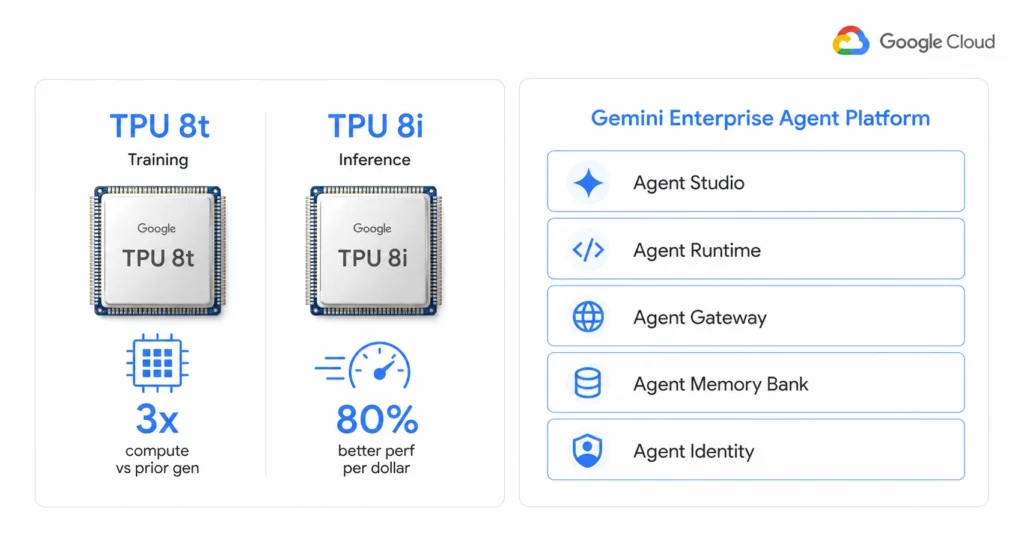
- Google split its AI compute into two specialized 8th-generation TPU chips – TPU 8t for training and TPU 8i for inference – with TPU 8i delivering 80% better performance per dollar than the prior generation.
- Vertex AI was superseded by the Gemini Enterprise Agent Platform, a new unified stack for building, scaling, governing, and optimizing agents. Pricing for Agent Runtime, Sessions, Memory Bank, and Code Execution began billing in February 2026.
- BigQuery fluid scaling launched, reducing costs by up to 34% on average for autoscaling workloads – the most direct cost reduction announced for existing GCP customers at the event.
For FinOps teams, three things require immediate attention: the new Agent Runtime billing model affects every team running Vertex AI agents, the C4N and M4N VM families change the CUD sizing calculus for compute-heavy workloads, and BigQuery fluid scaling may reduce your bill without any action if autoscaling is already enabled.
All pricing figures in this document require verification at cloud.google.com/pricing before acting on them.
Google Cloud Next 26 – April 22-24: The Five Headline Announcements
Google Cloud Next 26 drew 32,000 attendees to Las Vegas and produced more announcements in three days than any prior Next event. Five carry direct relevance for teams managing GCP infrastructure and cost.
1. Gemini Enterprise Agent Platform Replaces Vertex AI as the Primary AI Entry Point
The biggest structural change at Next 26: Vertex AI is being superseded by the Gemini Enterprise Agent Platform. J.P. Morgan described this as “effectively superseding Vertex AI” – integrating enterprise building, orchestration, governance, and security into a single entry point rather than dispersed functional modules.
Key components that launched or entered preview at Next 26:
- Agent Studio – no-code agent builder with export to Agent Development Kit (ADK) for full-code environments.
- Agent Runtime – compute layer for agents. Delivers sub-second cold starts. Pricing: per vCPU-second and GiB-second of actual execution. Free tier: 180,000 vCPU-seconds and 360,000 GiB-seconds per month. Idle agent time is not billed.
- Agent Memory Bank – long-term memory across conversations. Using Memory Profiles for high-accuracy, low-latency recall.
- Agent Identity – cryptographic ID per agent creating an auditable trail for every action mapped to IAM authorization policies.
- Agent Gateway – unified control point managing agent fleet connectivity with Model Armor protections against prompt injection and data leakage.
- Long-running agents – execute complex business processes autonomously in secure cloud sandboxes without constant prompting.
Cost implication: Agent Runtime billing began on February 11, 2026 for Code Execution, Sessions, and Memory Bank. Teams running Vertex AI agents that have not updated their cost models are likely already seeing new line items.
2. Eighth-Generation TPUs: Two Chips, Two Workloads, One Cost Model Change
Google announced two distinct 8th-generation TPU chips at Next 26 – the first time a TPU generation has shipped as two separate products rather than one.
| TPU | Primary Use | Key Spec | Performance vs Prior Gen | Cost Position |
|---|---|---|---|---|
| TPU 8t (training) | Large-scale model training | 9,600 chips per superpod, 121 exaflops | Nearly 3x higher compute performance | Targeted at frontier AI development |
| TPU 8i (inference) | Agent inference and RL workloads | 384 MB on-chip SRAM, 288 GB HBM | 80% better performance per dollar | Lower per-token inference cost than prior gen |
TPU 8t targets Anthropic-scale training jobs. TPU 8i is the cost story for enterprise teams. The 80% performance-per-dollar improvement on inference means that teams currently running large inference workloads on TPU v5e should model whether the new generation reduces effective per-token costs before the next CUD renewal cycle.
TPU 8t and TPU 8i will be available to Cloud customers soon. Pricing had not been published at time of writing.
3. BigQuery Fluid Scaling Reduces Costs up to 34% on Autoscaling Workloads
BigQuery fluid scaling launched at Next 26. Google stated it lowers costs by up to 34% on average for autoscaling workloads. The mechanism: fluid scaling dynamically right-sizes compute allocation to match actual query demand rather than provisioning for peak capacity.
This is the most directly actionable cost reduction announced at Next 26 for teams already running BigQuery. If autoscaling is enabled in your BigQuery environment, fluid scaling may reduce your bill with no code or configuration changes required. If autoscaling is not enabled, enabling it is now more financially attractive than before.
For teams evaluating BigQuery commitment strategy alongside this cost reduction, the Usage.ai guide on GCP Committed Use Discounts covers when to use spend-based BigQuery CUDs and how to size them against actual consumption.
4. Agentic Data Cloud: Cross-Cloud Lakehouse, Spanner Omni, and Knowledge Catalog
The Agentic Data Cloud announcement grouped several database and data platform updates:
- Spanner Omni (Preview) – runs Spanner beyond Google Cloud: across multiple clouds, on-premises, or locally. Brings Spanner’s globally consistent, multi-model database to hybrid and multicloud environments.
- Spanner Columnar Engine – accelerates analytical queries up to 200x on live operational data using vectorized execution without impacting transactional workloads.
- Cross-Cloud Lakehouse – cross-cloud interconnect integration into the data plane, Apache Iceberg REST Catalog, and bi-directional federation in preview.
- Knowledge Catalog – grounds agents in trusted business context across the entire data estate.
- Lightning Engine for Apache Spark – up to 2x the price-performance over proprietary alternatives.
- Managed Lustre – up to 10 terabytes per second of throughput for high-performance storage workloads.
- Bigtable in-memory tier – sub-millisecond read latency for latency-sensitive workloads.
5. Virgo Network and Axion N4A: Infrastructure Cost Changes for Agent Workloads
Two infrastructure announcements at Next 26 change the cost model for AI and agent workloads at the compute layer.
Virgo Network is Google’s new megascale AI data center fabric linking 134,000 TPU 8t chips with up to 47 petabits per second of non-blocking bisectional bandwidth. It delivers up to 4x the bandwidth per TPU 8t accelerator compared to the previous generation and 40% lower unloaded fabric latency. For teams running distributed training at scale, this means training checkpoints and recoveries happen faster, keeping accelerators at 95% utilization or higher.
Axion N4A instances are powered by Google’s custom Arm-based Axion CPU and are positioned as the optimal compute layer for agent runtimes. Google stated GKE Agent Sandbox with N4A offers up to 30% better price-performance than agent workloads on other hyperscalers. If your agent orchestration workloads currently run on x86 instances, N4A is worth benchmarking before the next CUD purchase.
Compute and Containers: New VM Families, GKE Agent Sandbox, and Reserved Capacity
New VM Families: C4N and M4N
Google launched C4N and M4N VM families at Next 26 as part of the cross-cloud infrastructure updates.
- C4N – compute-optimized instances with enhanced networking, part of the 4th-generation Compute Engine portfolio. Optimized for RL reward calculation, agent orchestration, and nested visualization.
- M4N – memory-optimized instances for high-memory workloads. Supplements the existing M3 family.
For FinOps teams with CUD coverage on C4 or M3 instances: new families typically do not inherit existing resource-based CUD coverage. Before migrating workloads from C4 or M3 to C4N or M4N, check whether your resource-based CUDs cover the new family. If not, a new commitment is required for the migration to deliver savings.
For GCP compute pricing details by instance family and how CUD discounts apply to each series, see the Usage.ai guide at Google Cloud Compute Pricing Guide.
GKE Agent Sandbox and GKE Improvements
GKE received several updates in April 2026 relevant to cost and operations:
- GKE Agent Sandbox – now available for everyone. Provides a hardened environment to safely execute model-generated code and browser-based automation. Works with Axion N4A for 30% better price-performance than other hyperscalers on agent workloads.
- Ambient networking for GKE and Cloud Run – new integrated data plane providing service discovery, zero-trust access, and traffic management without sidecar proxies. Removes the sidecar compute overhead that previously added ~15-20% CPU to mesh-enabled pods.
- GKE Kubernetes 1.35 features including in-place Pod Resize (change CPU/memory without restart) and writable cgroups. In-place resizing tightens right-sizing by allowing resource adjustment without downtime.
The ambient networking update is particularly relevant for cost: removing sidecar proxies reduces per-pod compute consumption. For teams running Istio or Linkerd service meshes, evaluate whether ambient mode reduces your effective node count before the next CUD purchase cycle.
Calendar-Mode Future Reservations Now Generally Available
Compute Engine made future reservation requests in calendar mode generally available. Teams can now reserve high-demand GPUs, TPUs, or H4D resources up to 90 days in advance for scheduled windows. This directly addresses the capacity planning challenge for time-boxed AI training runs, where securing GPU or TPU availability at a known cost is critical for budget accuracy.
Calendar-mode reservations are distinct from CUDs. They guarantee capacity for specific time windows but do not provide the continuous discount rate that CUDs deliver. For ongoing inference or serving workloads, CUDs remain the correct cost tool. For scheduled batch training jobs, calendar-mode reservations ensure capacity is available when needed.
Data and AI: Vertex AI Pricing Changes, Gemini 3.1 Pro, and BigQuery Updates
Gemini 3.1 Pro Now in Preview on Vertex AI
Google announced Gemini 3.1 Pro in preview in early April 2026, ahead of Next 26. The model is available in Vertex AI and Gemini Enterprise. Google described it as “noticeably smarter and more capable for complex problem-solving.”
Pricing for Gemini 3.1 Pro had not been published at time of writing. The prior model, Gemini 2.5 Pro, was priced at $1.25 per million input tokens (up to 200K context), $2.50 for longer contexts, and $10-$15 per million output tokens on Vertex AI. Gemini 3.1 Pro pricing should be verified before including it in AI spend forecasts.
Vertex AI Agent Engine: Billing Began February 11, 2026
A critical billing change that predates Next 26 but requires action in April: Google announced that billing for Vertex AI Agent Engine Code Execution, Sessions, and Memory Bank began on February 11, 2026.
Teams running Vertex AI agents that launched after February 11 without updating cost models are now incurring charges they may not have forecasted. The Agent Runtime free tier covers 180,000 vCPU-seconds (50 hours) and 360,000 GiB-seconds (100 hours) per month. Once above those thresholds, billing accrues at published rates.
Recommended action: pull Agent Runtime usage from Google Cloud Billing for February and March 2026 to establish the actual cost baseline before building April forecasts.
BigQuery: Fluid Scaling, Autonomous Embedding, and Billing Export Updates
BigQuery received three meaningful updates this month beyond the fluid scaling announcement at Next 26:
- Fluid scaling – up to 34% average cost reduction on autoscaling workloads. Available for teams using BigQuery autoscaling.
- Autonomous embedding generation on tables (Preview) – maintains embeddings as data changes and enables semantic search via AI. Billing implications: embedding generation runs on the BigQuery compute layer. Volume-heavy tables may see increased query costs if embedding refresh is triggered frequently.
- Cloud Billing detailed export to BigQuery now includes granular Pub/Sub snapshot, subscription, and topic usage via resource.name and resource.global_name fields. This enables accurate per-resource cost analysis for Pub/Sub and makes chargeback and anomaly detection for messaging spend more reliable.
Security: Agentic Defense, Wiz Integration, and Privileged Access Manager
Agentic Defense: Google Threat Intelligence Plus Wiz
Google launched Agentic Defense at Next 26 – a cybersecurity platform combining Google Threat Intelligence and Security Operations with Wiz’s Cloud and AI Security Platform. The combined offering covers:
- Wiz AI Application Protection Platform (AI-APP) – autonomous protection from code to cloud to runtime across multicloud, hybrid, and AI environments.
- Agent Anomaly Detection – detects suspicious agent behavior in real time using statistical models and an LLM-as-a-judge framework.
- Agent Security Dashboard – powered by Security Command Center, unifies threat detection and risk analysis, maps relationships between agents and models, and automates asset discovery.
Cost implication: Wiz integration is a new billable service layer on top of existing Google Cloud Security operations pricing.
Privileged Access Manager: Agent Identities as Grant Requesters
Privileged Access Manager now supports agent identities as grant requesters and approvers, currently in preview. This allows AI agents to be granted time-limited elevated permissions within defined authorization policies – eliminating the pattern of permanently elevated service accounts that has been a standing security gap in agentic deployments.
From a cost governance perspective, this is also relevant: agents with permanently over-provisioned IAM permissions may be accessing services or APIs beyond what their workload requires, generating unnecessary spend. Auditing agent permissions as part of cost analysis is now a supported workflow.
FinOps and Cost Management: What April 2026 Means for GCP Spend
Committed Use Discounts and the New VM Families
C4N and M4N are the two VM families most likely to affect CUD strategy for compute-heavy teams. The core risk: existing resource-based CUDs are tied to specific machine series. Migrating workloads from covered series (C4, M3) to new families (C4N, M4N) moves usage out of CUD coverage and back to on-demand rates unless new commitments are purchased.
Recommended action before migrating to C4N or M4N: pull your current resource-based CUD coverage by machine series from the Google Cloud Console. If the new families are not yet covered, estimate the CUD savings rate available for the new series and factor the commitment cost into the migration ROI model.
The full mechanics of GCP resource-based versus spend-based CUDs, including how to size and layer commitments across machine families, are covered in the Usage.ai guide on GCP Cost Optimization.
BigQuery Fluid Scaling Is a Passive Savings Opportunity
Unlike most GCP cost changes that require active decisions, BigQuery fluid scaling delivers savings without configuration changes for teams already using autoscaling. The 34% average reduction figure is a Google-stated average across workloads. Actual savings will vary by query pattern and data volume. Monitor BigQuery billing line items weekly for the first 30 days after enabling autoscaling to establish the new baseline before buying or renewing BigQuery CUDs.
Vertex AI Agent Runtime Billing – Check February and March Invoices
The February 11, 2026 billing start date for Agent Runtime, Sessions, Memory Bank, and Code Execution is the highest-priority financial action item from April for GCP teams. Teams that onboarded Vertex AI agents before that date without updating cost models have two months of charges to review.
Pull billing by service and SKU for February and March from Cloud Billing or BigQuery billing export. Filter for Vertex AI Agent Platform SKUs. Compare against any existing budget alerts. If charges exist that were not forecasted, build a retroactive estimate of monthly spend going forward and update budgets accordingly before May 1.
T4 GPU Retirement Timeline Requires Action
Google is retiring legacy NVIDIA T4 GPU instances by Q2 2026. Teams still running critical workloads on T4 GPUs need to migrate to NVIDIA L4 or A100 instances before the retirement date to avoid disruption.
Migration incentives and new sustained-use discounts provide cost reductions up to 30% on newer GPU families including L4 and A100. The cost of migration to L4 or A100 is offset by the higher performance per dollar on both families. If your team is running T4 instances under a resource-based CUD, verify whether the CUD covers the target instance family before migrating.


